Architecting Multi-Region SaaS for Minimum Egress: Patterns and Tradeoffs

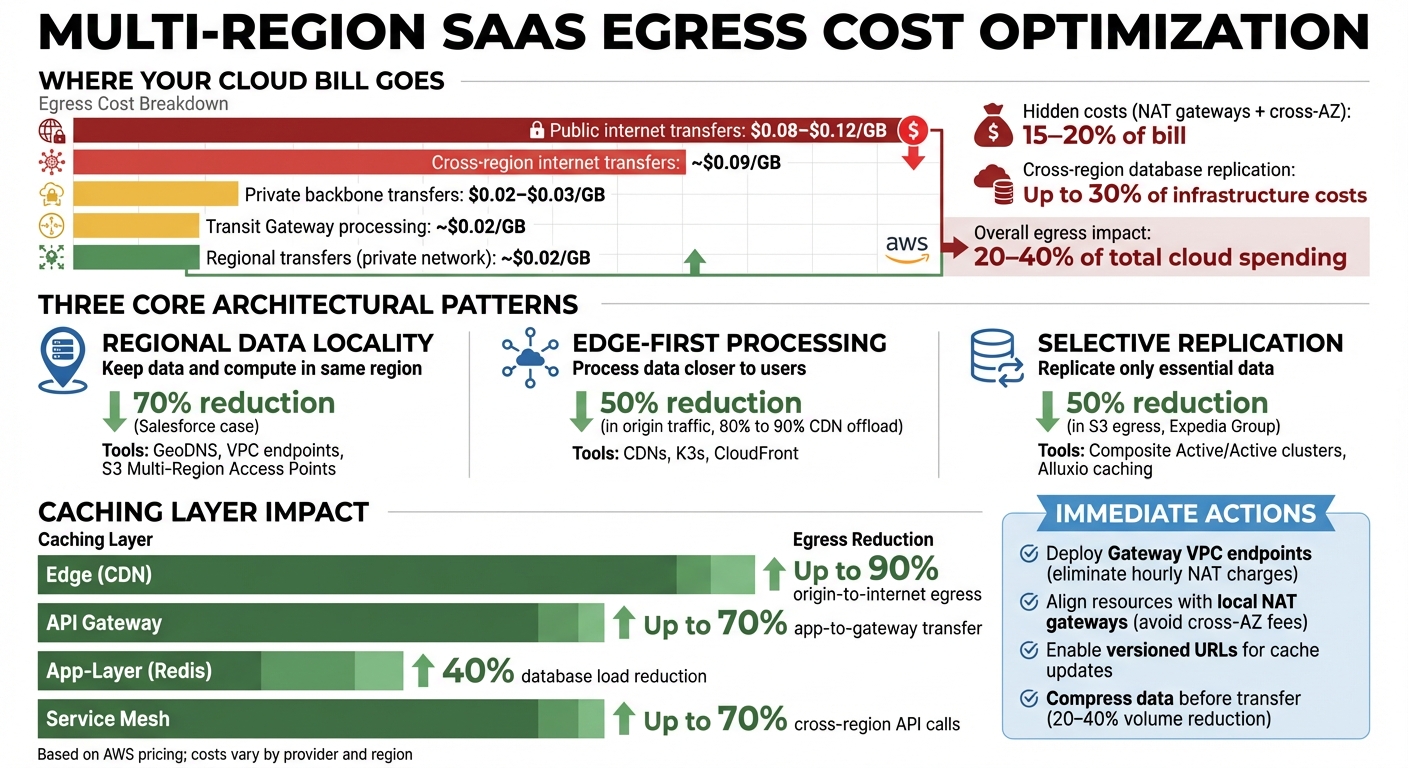
Egress costs can quietly inflate your cloud bill by 20–40%. For SaaS platforms operating across multiple regions, these costs are often unpredictable and driven by architectural choices. The good news? You can reduce these expenses with smarter strategies.
Key Takeaways:
- Egress Costs Breakdown:
- Public internet transfers: $0.08–$0.12/GB.
- Cross-region database replication: Up to 30% of infrastructure costs.
- Hidden fees like NAT gateways and cross-AZ traffic can add 15–20% to your bill.
- Effective Solutions:
- Regional Data Locality: Keep data and compute in the same region to avoid unnecessary transfers.
- Edge-First Processing: Process and filter data closer to users to minimize movement to central servers.
- Selective Replication: Only replicate essential data globally to control costs.
- Tools and Techniques:
- Use GeoDNS for directing users to the nearest region.
- Leverage CDNs for caching both static and dynamic content.
- Monitor egress using tools like AWS Cost Explorer and VPC Flow Logs.
The Bottom Line:
By combining these strategies, you can cut egress costs, improve performance, and avoid unexpected cloud bills. The tradeoff? Balancing cost savings with operational complexity and performance needs.
Multi-Region SaaS Egress Cost Comparison: Architectural Patterns and Data Transfer Pricing
Reducing cloud egress charges: 10 common pitfalls and how to avoid them [Cloud Masters #121]
sbb-itb-f9e5962
Architectural Patterns for Reducing Egress Costs
Keeping egress costs under control isn’t just about keeping tabs on your data transfers – it’s about building your architecture from the ground up to limit unnecessary data movement. Three key approaches can help: regional data locality, edge-first processing, and selective replication. Let’s break these down.
Regional Data Locality
The idea here is simple: keep your data and compute resources in the same region. By doing this, you can avoid hefty charges for moving data across regions or over the public internet. For example, regional transfers typically cost around ~$0.02 per GB, while public internet transfers can climb to ~$0.09 per GB.
One way to achieve this is by directing users to the nearest regional deployment using GeoDNS, which not only cuts costs but can also help with compliance requirements like GDPR. For instance, using tenant-specific subdomains (e.g., tenant1.app.com) ensures data stays local.
Another tactic involves keeping internal traffic within the cloud provider’s private network. This can save a lot – transfers on the private backbone cost $0.02–$0.03 per GB, compared to $0.09 per GB over the internet. For example, replicating 10 TB of data monthly between US-East-1 and EU-West-1 could rack up over $900 in egress charges.
To further reduce costs, VPC endpoints can eliminate NAT Gateway fees. A great example comes from Salesforce, which switched to using S3 Multi-Region Access Points with VPC Interface Endpoints. This change cut their data movement costs by about 70%.
"Using S3 Multi-Region Access Points and VPC Interface Endpoints allowed Salesforce to write data directly to Amazon S3 over the private AWS network… for about 70% less cost than the previous architecture."
– AWS Storage Blog
Of course, these optimizations come with tradeoffs. For instance, managing a network of VPC peering connections can get complicated as your architecture scales. While using a Transit Gateway simplifies management, it adds a processing fee of about $0.02 per GB. Additionally, designing effective data synchronization and caching solutions is critical to avoid unnecessary cross-region transfers.
Edge-First Processing
Processing data closer to the user – at the edge – can significantly reduce the amount of data that needs to travel back to your main infrastructure. This is particularly effective for applications like IoT, real-time analytics, and API-driven services. The idea is to process, filter, and aggregate data at the edge, sending only the most relevant information back to the cloud.
Take IoT sensors, for instance. Instead of transmitting thousands of raw readings, they can calculate hourly averages or send alerts only when thresholds are exceeded. This reduces both bandwidth usage and egress costs.
Modern CDNs also play a big role here. Beyond caching static content, they can now cache dynamic API responses, taking a load off your origin servers. For example, increasing CDN offload from 80% to 90% can cut traffic to the origin by 50%. In 2022, Slack used Amazon CloudFront as a reverse proxy for its API, which halved their global API response times by leveraging AWS’s private backbone.
"When the origin is hosted on AWS, those [CloudFront] charges replace Data Transfer Out charges that would otherwise apply to the origin."
– Achraf Souk, Edge Specialist Solutions Architect, AWS
For distributed SaaS applications, an Edge Stack can handle tasks like protocol translation, caching, and local business logic. Lightweight Kubernetes distributions, such as K3s, make it easier to standardize orchestration across both edge and cloud environments with minimal resource requirements.
However, edge-first processing isn’t without challenges. Edge nodes must be able to function independently, with local persistence and decision-making capabilities. This means building robust systems for buffering data during connectivity disruptions and ensuring smooth batch synchronization.
Selective Replication Strategies
Not all data needs to be replicated globally. Selective replication focuses on identifying what truly requires multi-region availability and what can stay localized. This approach can make a big difference in reducing egress costs.
Start by categorizing workloads based on access patterns. For example, user-generated content might only need to exist in the user’s home region, while shared resources like product catalogs might benefit from broader replication. For databases, using Composite Active/Active or Composite Active/Passive clusters allows for localized reads and writes. Tools like the Tungsten Connector can route users to the correct regional master based on their location.
Consistency models also matter. Strong consistency requires synchronous replication across regions, which can drive up costs. On the other hand, eventual consistency uses asynchronous replication, lowering costs but introducing temporary data delays.
For high-write applications, parallel replication with multiple apply threads can minimize lag without increasing synchronous traffic. Expedia Group provides a great example of this strategy: by using Alluxio as a caching layer, they served frequently accessed data locally, cutting cross-region S3 egress costs by 50% and improving latency.
The main tradeoff here is balancing cost and availability. While aggressive replication improves disaster recovery and global access speeds, it also increases egress fees. Selective replication, though more economical, requires careful planning around user access patterns, data residency, and consistency requirements. Regular audits are essential to avoid silent cost accumulation from tools like S3 Cross-Region Replication.
Together, these architectural patterns provide a roadmap for reducing egress costs while maintaining strong performance and reliability.
Caching and Content Delivery Optimization
To trim down cross-region data transfers and cut egress costs, caching and efficient content delivery play a critical role. By storing frequently accessed data closer to users, caching not only reduces costs but also speeds up applications. A robust caching strategy operates across multiple layers: at the edge using CDNs, at the gateway level, and within your application itself.
CDN Deployment for Static and Dynamic Content
CDNs (Content Delivery Networks) deliver content from servers located near your users, significantly reducing the need for origin server requests. For static assets like images, videos, and scripts, CDNs can reduce the load on origin servers by up to 90%. Modern CDNs now also cache dynamic API responses, enabling faster delivery of live content.
Using tiered caching enhances CDN efficiency. With this setup, lower-tier edge servers check upper-tier regional hubs before reaching out to the origin server. This approach improves cache hit ratios and reduces the load on origin servers, which helps avoid hefty egress fees. For instance, a user in Seattle might receive a file from a West Coast hub instead of a distant origin server.
Anycast routing further improves performance by cutting latency and enhancing resilience against DDoS attacks. Unlike traditional DNS-based routing, Anycast uses BGP to direct traffic based on the user’s IP address, automatically rerouting to the nearest available node if one goes offline.
"CloudFront improves performance for both cacheable content (such as images and videos) and dynamic content (such as API acceleration and dynamic site delivery)."
– AWS
To avoid cache fragmentation, use custom cache keys and enable negative caching for error responses. Instead of manually invalidating caches (which can be rate-limited), implement versioned URLs (e.g., style.v2.css) to ensure immediate updates across the CDN.
Beyond edge caching, optimizing back-end caching layers can further reduce the strain on origin servers.
Distributed Application-Layer Caching
Application-layer caching complements regional data storage and edge-first processing by localizing data retrieval. Tools like Redis and Memcached store frequently used data – such as session states, database query results, or API responses – locally within each region. This avoids costly cross-region database calls and can reduce database load by up to 40% during peak times.
For application-layer caching, deploying regional Redis clusters is key. When a user request comes in, the application first checks the local cache. If the data isn’t found (a "miss"), it retrieves the information from the database and caches it for future use. For multi-tenant SaaS setups, tenant-aware caching is essential. By prefixing cache keys with tenant IDs (e.g., tenant:123:resource:456), you can isolate data and manage expiration effectively.
Common cache invalidation strategies include:
- Time-based (TTL): Automatically expires data after a set duration.
- Event-based: Uses pub/sub mechanisms to invalidate cache entries when data changes.
- Version-based: Appends version identifiers to objects, ensuring clients fetch updated data.
API gateways can also cache responses, reducing backend load by as much as 70%. This reduces the volume of data transferred from application servers, cutting egress costs.
| Caching Layer | Primary Benefit | Egress Impact |
|---|---|---|
| Edge (CDN) | Lowers latency for global users | Reduces origin-to-internet egress by up to 90% |
| API Gateway | Reduces backend processing | Lowers app-to-gateway data transfer by up to 70% |
| App-Layer (Redis) | Avoids redundant DB queries | Minimizes cross-region/cross-AZ database egress |
| Database (Read Replicas) | Localizes read traffic | Eliminates cross-region egress for read-heavy workloads |
Service Mesh and Traffic Optimization
Service meshes, like Istio or Linkerd, help keep inter-service traffic local, reducing unnecessary cross-region data transfers. These tools manage retries, circuit breaking, and load balancing intelligently. For example, if a service call fails, a naive retry might send the request to a different region, incurring cross-region egress fees. A service mesh ensures retries stay within the same region, only failing over to another region as a last resort.
Service meshes also enable locality-aware load balancing, prioritizing endpoints within the same availability zone or region. This reduces cross-region traffic and improves cost efficiency. With proper configuration, global load balancers can cut cross-region API calls by up to 70% by directing users to the nearest regional endpoint.
Additionally, service meshes provide detailed telemetry, offering insights into traffic patterns that drive up egress costs. By analyzing this data, you can identify and refactor services that generate excessive cross-region calls. While service meshes add some operational complexity, the potential savings and reliability improvements often outweigh the effort for large-scale, multi-region SaaS applications.
Monitoring and Managing Egress Costs
Keeping tabs on egress costs requires precise tracking. Providers like AWS offer tools such as Cost Explorer, which allows you to filter data transfers by region, availability zone (AZ), and resource type. For more detailed insights, AWS provides Cost and Usage Reports (CUR) 2.0, which deliver hourly billing data. This data can be exported to Amazon S3 and analyzed using Amazon Athena with SQL – perfect for spotting trends over time.
Cloud Provider Tools for Egress Cost Tracking
Both AWS and Google Cloud provide tools to help track and categorize egress costs. For example, Google Cloud‘s Billing Reports include a "Group by" feature to summarize costs by region or multi-region. AWS’s Cost Allocation Tags and Google Cloud’s Labels allow you to categorize expenses by project, environment, or component. While enabling these tags might take up to 24 hours, they’re invaluable for identifying which teams or services are driving costs.
For real-time monitoring, Amazon CloudWatch can track bandwidth usage through NAT and internet gateways, with options to set alerts for unusual spikes. AWS Cost Explorer provides up to 13 months of historical data and can even forecast spending for the next 18 months. These tools make it easier to move from reactive billing surprises to proactive cost management.
| Feature | AWS Tools | Google Cloud Tools |
|---|---|---|
| Primary Analysis Tool | Cost Explorer | Cloud Billing Reports |
| Deep-Dive Querying | CUR + Amazon Athena (SQL) | BigQuery Export (SQL) |
| Granular Metadata | Cost Allocation Tags | Resource Labels |
| Geographic Tracking | Usage Type (Region-to-Region) | Group by Location (Region) |
| Forecasting | Cost Explorer (18 months) | Gemini Cloud Assist |
Application Instrumentation for Data Transfer Analysis
While cloud tools give you a big-picture view, application instrumentation drills down to the details. For instance, VPC Flow Logs track traffic specifics, helping you see which resources are transferring data and in what volumes. Combining these logs with Amazon CloudWatch Contributor Insights can identify "top talkers", such as the IP addresses or resources responsible for the most inter-region or inter-AZ traffic.
For containerized environments, enabling Container Insights in Amazon ECS or EKS helps pinpoint which microservices are generating the most data transfer. You can even use custom Lambda functions to parse flow logs and measure traffic between specific availability zones, creating custom metrics for alerting. Pairing these network logs with application metadata in a database like DynamoDB adds another layer of visibility.
"You pay a Data Transfer charge when you send data out from AWS to Internet, between AWS Regions, or between Availability Zones (AZ)."
– Shiva Vaidyanathan, Senior Cloud Infrastructure Architect, AWS
For Kubernetes workloads, configuring topology.kubernetes.io/zone constraints ensures resources prioritize local-zone traffic, reducing costly inter-AZ transfers. Additionally, placing high-traffic resources in the same AZ as their NAT gateway can help you avoid cross-AZ charges.
Governance Mechanisms for Cost Control
Governance plays a crucial role in preventing unexpected egress costs. AWS Organizations’ Service Control Policies (SCPs) can block the creation of resources that lack essential cost-allocation tags, like Project, Owner, or Environment. By using Organizational Units (OUs), you can enforce these policies across multiple accounts as your infrastructure scales.
To manage costs effectively, establish baselines using three months of historical data to identify average and peak egress volumes. Set automated alerts to notify teams when egress spending exceeds 25% above these baselines. Typical variance thresholds range from 15–20% above average monthly costs, helping to separate normal growth from anomalies.
Regular reviews are also essential. Conduct quarterly architectural reviews to assess whether your multi-region setup is still cost-effective or if data processing should move closer to the source. Weekly reviews can catch unusual spikes, while monthly reviews can identify which applications are driving egress costs. Compressing data before transfer can also help – reducing volume by 20–40% and cutting egress charges. For further savings, use Gateway VPC endpoints for S3 and DynamoDB to keep traffic within the provider’s private network, eliminating hourly charges and lowering public data transfer costs.
Tradeoffs and Implementation Strategy
Balancing Cost, Performance, and Complexity
Optimizing egress involves making tradeoffs between cost, performance, and complexity. For example, active-active multi-region deployments can deliver response times under 50ms within regions. However, they come with higher infrastructure costs and added complexity, particularly with cross-region writes. On the other hand, active-passive setups are simpler and less costly, but they can result in higher latency for users far from the active region and potential downtime during failovers.
Replication strategies also involve compromises. Asynchronous replication offers faster write speeds but carries the risk of data loss during failovers. Meanwhile, synchronous replication ensures data consistency but introduces higher latency and tighter interdependencies. AWS Principal Solution Architect John Fermenta highlights this balance, stating:
"I have not come across an enterprise that every single application needs to be multiregion"
To navigate these tradeoffs, it helps to classify applications based on their business impact. This approach ensures that only the most critical workloads justify additional costs and complexity.
Phased Implementation for Egress Optimization
A phased approach offers a practical way to reduce egress costs while maintaining service quality. Start by establishing a baseline using tools like VPC Flow Logs, Cost Explorer, and CloudWatch to identify the primary drivers of data transfer costs. Tackle quick wins first – such as implementing Gateway VPC endpoints for S3 and DynamoDB. These endpoints are cost-effective because they avoid hourly charges and keep traffic within AWS’s private network. Additionally, ensure high-traffic resources are aligned with local NAT gateways to eliminate cross-AZ data transfer charges.
A real-world example: Salesforce managed to cut data movement costs by approximately 70% by replacing NAT Gateways and public S3 endpoints with Multi-Region Access Points and VPC Interface Endpoints. After testing these methods on a smaller scale, successful strategies can be rolled out across other high-volume workloads. Another effective tactic is using tenant-specific subdomains and DNS routing to direct users to regional stacks, reducing unnecessary cross-region authentication traffic.
Key Metrics and Lessons Learned
Tracking the right metrics is critical to ensure phased optimizations are effective. Monitor egress as a percentage of total cloud spending – this figure typically ranges from 20% to 40% for many enterprises. Compare this metric against your initial baseline to identify any significant changes. Keep an eye on performance metrics like regional response times (targeting under 50ms) and inter-region latency (aiming for less than 200ms) to ensure cost reductions don’t compromise user experience.
It’s also important to allocate egress costs to specific services or teams. This helps establish chargeback models and pinpoints the main cost drivers. Lastly, regularly test your failover strategy. As John Fermenta emphasizes:
"An untested DR strategy is not a DR strategy"
To ensure readiness, periodically run operations from standby regions and validate your disaster recovery processes.
FAQs
How do I find what’s driving my egress costs?
To get a handle on what’s pushing up your egress costs, take a closer look at your data transfer patterns. Use tools like cost explorers, VPC flow logs, or network visibility dashboards to dig into the details. Identify the sources and destinations responsible for high-volume transfers, especially across regions, availability zones, or different services. Once you’ve pinpointed the expensive data flows, you can focus on streamlining and optimizing those specific areas to cut down on costs.
When should I choose active-active vs active-passive multi-region?
When deciding between the two setups, consider your priorities:
- Active-active: This setup ensures high availability and resilience by having both regions actively handle traffic. It’s ideal if minimal downtime and data loss are critical. However, be prepared for increased costs and added complexity in managing the system.
- Active-passive: If you’re looking to prioritize cost savings and simplicity, this option may suit you better. It involves one active region and a standby region that takes over during failover. Keep in mind, this approach may result in longer recovery times and a higher risk of data loss.
What data should I replicate across regions?
In multi-region SaaS setups, data replication plays a key role in meeting latency requirements, compliance standards, and disaster recovery goals. The types of data often replicated include:
- Backups: Ensures recovery options in case of failures.
- Configuration Settings: Maintains consistency across regions.
- Critical Application Data: Keeps essential services running smoothly.
For scenarios where low latency or regulatory compliance is crucial, replicating databases or application state data becomes necessary. However, it’s important to weigh the trade-offs between consistency, cost, and latency. For example, data that’s non-essential or rarely accessed can remain in a single region to help cut down on egress costs. Balancing these factors ensures efficiency without compromising availability.