Why Change Failure Rate Matters for SaaS Startups

Change Failure Rate (CFR) measures how often deployments fail and need urgent fixes. For SaaS startups, a high CFR means more time fixing issues and less time building features that drive growth. Elite teams keep CFR between 0% and 5%, but most struggle to stay below 30%. Failures not only slow progress but also cost businesses up to $500,000 per hour during outages.
With AI now generating over 20% of code, CFR has become even more critical to monitor as AI can introduce fragile systems. Lowering CFR involves smaller, frequent changes, feature flags, automated rollbacks, and better testing. Tools like GitHub, LaunchDarkly, and Kubernetes can help track and reduce failures. A low CFR ensures stability, saves costs, and supports scaling as startups grow.
Change Failure Rate Benchmarks and Impact Comparison for SaaS Startups
What is Change Failure Rate? – The Four Key Metrics of DORA (Part 1)
What Is Change Failure Rate?
When discussing operational efficiency, it’s essential to understand Change Failure Rate (CFR). This DORA metric measures the percentage of production deployments that fail and require immediate fixes, such as rollbacks, hotfixes, or patches. CFR is a key indicator of stability, balancing out speed-focused metrics like deployment frequency.
In simple terms, CFR reflects the quality and reliability of your software delivery process. A low CFR indicates a stable IT environment with robust testing practices, while a high CFR often points to issues like flawed deployment processes, inadequate testing, or human errors.
"Change failure rate is critical to track because it demonstrates your team’s success at delivering reliable, stable code. Having strong scores when it comes to deployment frequency and lead time for changes is only impressive if you have a comparatively low change failure rate." – Natalie Lunbeck, Shipyard
Now, let’s break down how to calculate CFR.
How to Calculate CFR
The formula to calculate CFR is straightforward:
(Number of failed changes / Total changes) × 100
When calculating, exclude fixes for previous failures from the total, as they don’t represent new deployments. Similarly, avoid including failures caused by external factors like ISP outages or hardware malfunctions since these don’t reflect your team’s performance.
CFR works alongside other metrics like Deployment Frequency, Lead Time for Changes, and MTTR. A low CFR combined with high deployment frequency signals a well-oiled delivery process. On the other hand, if CFR rises while lead times shrink, it may indicate that speed is being prioritized at the expense of quality. Understanding CFR and how to calculate it helps you gauge performance against industry standards.
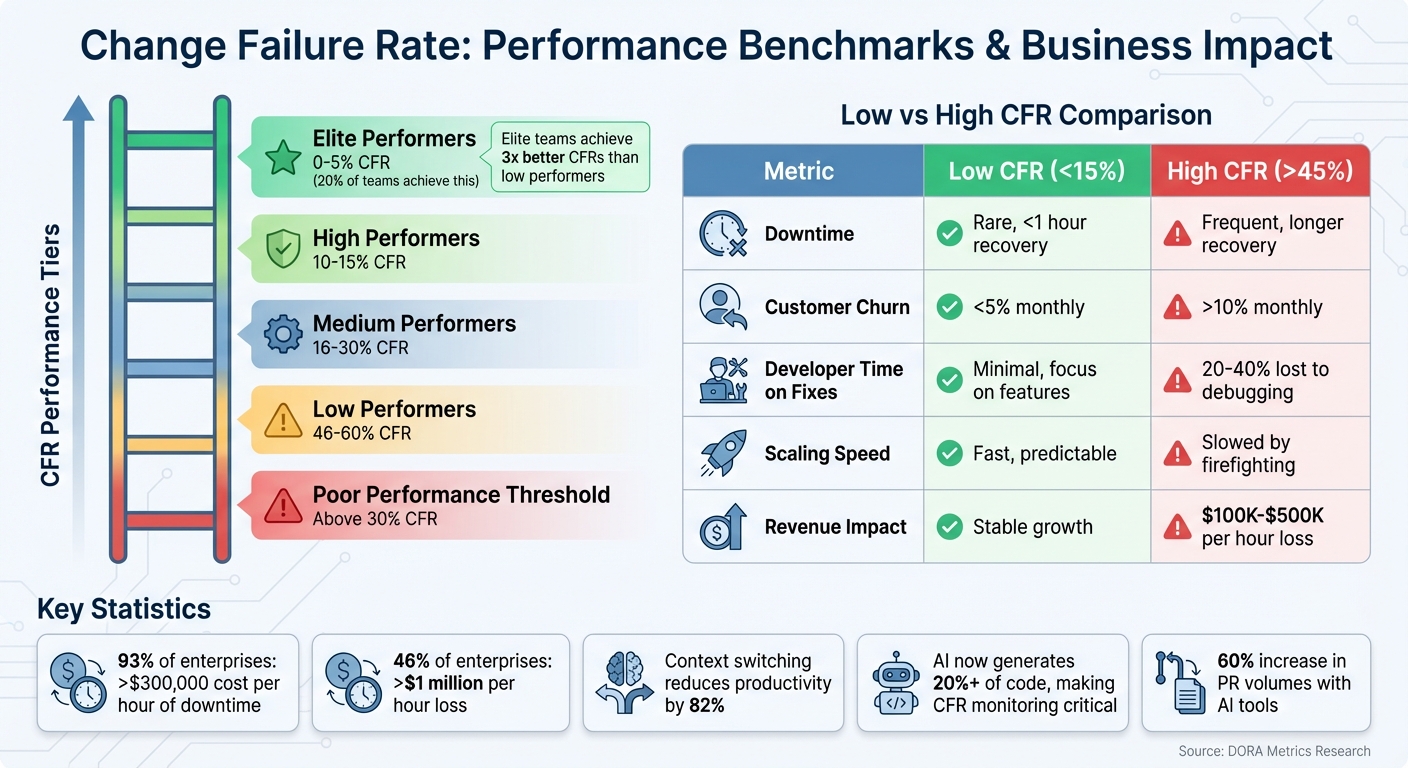
CFR Benchmarks for SaaS Startups
Industry data offers some useful benchmarks for CFR:
- Elite performers typically maintain a CFR between 0% and 5%. Only about 20% of teams achieve this level.
- High performers usually fall within the 10% to 15% range.
- Medium performers have a CFR between 16% and 30%.
- A CFR above 30% signals poor performance, with low performers experiencing rates between 46% and 60%.
Elite teams often achieve up to three times better CFRs than low performers. This translates to more time spent building new features and less time fixing production issues – a critical advantage for any SaaS startup.
How High CFR Hurts SaaS Startups
A high change failure rate (CFR) doesn’t just slow progress – it actively harms revenue, team efficiency, and customer trust. When deployments fail frequently, the effects ripple across the entire business, creating financial strain, operational chaos, and obstacles to scaling. Let’s break down how high CFR drives up costs, stifles growth, and contrasts with the benefits of a low CFR environment.
Business Costs of High CFR
Frequent deployment failures can be a financial black hole. For 93% of enterprises, just one hour of downtime can cost over $300,000, with 46% reporting losses exceeding $1 million per hour. For Fortune 1000 companies, infrastructure failures average $100,000 per hour, while critical application outages can surge to $500,000 per hour.
But the financial toll doesn’t stop at lost revenue. High CFR also piles on operational costs. Failed deployments often require emergency fixes, rollbacks, and overtime for engineering teams. These disruptions force developers into constant context switching, which can slash productivity by up to 82%.
The customer side of the equation is just as grim. Frequent outages and performance issues erode trust, leading to a 21% higher churn rate. Even a one-second delay can reduce conversion rates by 7%. Take Shopify’s Black Friday outage in November 2019 as an example: unexpected traffic overwhelmed its systems, causing an infrastructure failure that impacted thousands of businesses and resulted in an estimated $15 million in lost revenue – within just one hour.
Scaling Risks with High CFR
As SaaS startups grow, their systems become more complex, and the risks of high CFR multiply. A solution that works for 100 users can collapse under the weight of 10,000. At scale, a single failed deployment can trigger a domino effect, disrupting interconnected systems and critical functions. This makes balancing rapid innovation with operational stability a constant challenge.
High CFR traps teams in a reactive cycle, where developers are stuck fixing problems instead of building the scalable infrastructure needed for growth. Without stable processes, scaling safely becomes nearly impossible. Consider the case of Robinhood in March 2020: a two-day outage caused by issues in DNS resolution and backend databases halted trades during high market volatility. The result? Over $5 million in losses and legal backlash.
Rushed fixes to address failed changes often bypass proper security reviews, which can introduce vulnerabilities or lead to regulatory non-compliance – especially a concern for industries with strict standards.
"Nothing saps a development team’s spirit quite like a string of failed deployments. The constant firefighting leads to burnout and decreased job satisfaction." – Jesse Sumrak, LaunchDarkly
These challenges highlight the importance of measuring and reducing CFR, as explored in the next section.
Low CFR vs. High CFR Comparison
The differences between a low CFR and a high CFR environment couldn’t be clearer:
| Metric | Low CFR (<15%) | High CFR (>45%) |
|---|---|---|
| Downtime Frequency | Rare incidents, quick recovery (<1 hour) | Frequent outages, longer recovery times |
| Customer Churn | <5% monthly, strong trust | >10% monthly, damaged reputation |
| Developer Time | Focused on innovation and new features | 20–40% lost to debugging and emergency fixes |
| Scaling Speed | Predictable, fast iterations | Slowed by bottlenecks and constant firefighting |
| Revenue Impact | Stable growth, minimal disruption | Significant losses ($100K–$500K per hour) |
Ignoring scalable architecture doesn’t just slow down growth – it can be devastating. Businesses that neglect infrastructure lose between 8% and 28% of revenue, and 76% of digital transformation efforts fail to scale due to poor system performance and infrastructure limitations.
sbb-itb-f9e5962
How to Measure and Reduce CFR
To start, you need to define what qualifies as a failure. In this context, a failure is any change to production that demands immediate action – like a rollback, hotfix, or emergency patch. But here’s a tip: if you count hotfixes as new deployments, you’ll skew your failure rate artificially. The formula for calculating CFR is straightforward: (failed changes ÷ planned deployments) × 100. Now, let’s explore how CI/CD tools make tracking this metric easier.
Tracking CFR with CI/CD Tools
Most SaaS startups already have the tools they need to monitor CFR. For example, GitHub’s REST API and GitLab‘s Deployment API automatically log deployment results – whether they’re successful, failed, or encounter errors. Pair these with incident management platforms like PagerDuty or Sentry to establish a clear failure definition. This could be anything from an alert firing to a system slowdown logged in DataDog, or even a bug that requires a rollback.
To get a fuller picture, track CFR alongside related metrics like "Unreviewed Pull Requests", which can indicate potential risks, and "PR Size", since smaller pull requests tend to have lower failure rates. Tools such as Axify, Code Climate Velocity, and Jellyfish can automate this tracking. Even a simple dashboard linked to your CI/CD setup can do the trick, keeping the process efficient and accessible.
Strategies to Lower CFR
Lowering CFR starts with shipping smaller, more frequent changes. These smaller pull requests move through the pipeline faster, are easier to test, and limit the impact when problems arise. Take Onefootball as an example: in June 2025, they adopted a Kubernetes migration and monitoring strategy using New Relic. This approach reduced incidents by 80% and saved 40% of developer time previously spent on troubleshooting.
Feature flags are another game-changer. They let you separate deployment from release, meaning you can push updates to production without immediately making them visible to users. Tools like LaunchDarkly allow for gradual rollouts or provide an instant "kill-switch" to disable problematic features without redeploying. Pair this with automated rollbacks using methods like blue-green deployments or canary releases to minimize downtime when post-deployment health checks fail.
Additionally, shift-left testing can catch bugs early in the process. By embedding automated unit, integration, and end-to-end tests directly into your CI/CD pipeline, you can identify issues before they reach production. Using ephemeral environments – temporary, isolated setups for each pull request – also allows teams to test features thoroughly before they hit staging or production. Lastly, conducting blameless post-mortems after failures can help uncover root causes and refine your processes for the future.
"Investing in reducing your change failure rate isn’t just good DevOps practice – it’s smart business strategy." – Jesse Sumrak, LaunchDarkly
These strategies lay the groundwork for specialized tools that can further help you reduce CFR.
How TechVZero Helps Reduce CFR
Reducing CFR is essential for maintaining stability as your business grows, and TechVZero offers a targeted solution. Often, infrastructure instability is a hidden culprit behind high CFR. TechVZero addresses this by guiding SaaS startups through bare metal Kubernetes migrations. This approach not only reduces infrastructure costs by 40–60% but also improves system reliability, helping to lower CFR.
With experience managing systems at a scale of over 99,000 nodes, TechVZero is ideal for teams of 10–50 people who may not have the resources to hire dedicated infrastructure experts. Their performance-based model is simple: they take 25% of the savings for a year, and if no savings are achieved, there’s no fee. They also streamline compliance with SOC2, HIPAA, and ISO standards, aligning it with your timeline rather than dragging it out over months.
Conclusion
Keeping a low Change Failure Rate (CFR) is a game-changer for growth. When deployments are dependable, engineering teams can focus on creating features that draw in customers instead of constantly dealing with production issues. Elite teams typically keep their CFR between 0% and 5%, which allows for faster progress and innovation. On the other hand, teams with a CFR exceeding 30% often find themselves stuck in a cycle of maintenance work that adds little value to the business.
The impact of deployment failures goes beyond just numbers. A single failure can cost an engineer up to 20 minutes of deep focus. In more disruptive environments, the loss can be staggering – up to 82% of productive work time may be wasted.
Fast forward to 2026: with AI now responsible for generating over 20% of merged code, keeping a close eye on CFR is no longer optional. While AI tools have increased pull request volumes by 60%, a poorly managed CFR can lead to a growing quality gap, piling up technical debt at an alarming rate. This shift highlights the critical need to strike a balance between speedy delivery and maintaining rock-solid stability.
FAQs
Why is Change Failure Rate important for SaaS startups?
Change Failure Rate (CFR) is a key metric that reveals how reliable and stable your software deployments are. If your CFR is high, it means more changes are failing, which can lead to downtime, slower recovery times, and unhappy customers. And let’s face it – frustrated customers can quickly lose trust, which can hurt growth and make scaling your business feel like an uphill battle.
On the flip side, keeping your CFR low paves the way for smoother operations and happier customers. Reliable deployments not only boost performance but also lay the groundwork for a business that’s built to last. Focusing on this metric can help you maintain customer loyalty and set the stage for long-term success.
How can SaaS startups lower their Change Failure Rate (CFR)?
Reducing the Change Failure Rate (CFR) is essential for SaaS startups aiming to grow while maintaining reliable systems. One way to achieve this is by implementing practices like automated testing and infrastructure as code. These approaches catch potential issues early, helping to avoid deployment failures. On top of that, strategies such as canary releases, blue-green deployments, and rolling updates can limit the impact of problematic changes and make it easier to roll back if something goes wrong.
Equally important is clearly defining what qualifies as a failure and tracking it consistently. This allows teams to spot trends, investigate root causes, and focus on specific areas for improvement. Building a culture of continuous improvement – with regular monitoring, feedback loops, and adjustments to deployment processes – further ensures ongoing reductions in CFR and strengthens system reliability over time.
Why should SaaS startups track Change Failure Rate along with Deployment Frequency?
Tracking Change Failure Rate along with Deployment Frequency offers valuable insight into the efficiency and reliability of your software delivery process. Deployment Frequency measures how often your team releases updates, while Change Failure Rate highlights how often those updates result in problems like bugs or system downtime.
Keeping an eye on both metrics allows SaaS startups to balance speed with stability. This dual focus helps teams spot trends, minimize post-deployment issues, and create a more seamless scaling experience. In the long run, it strengthens customer trust and lays the groundwork for sustained success.