AI Incident Data: Retraining Models for Continuous Learning

When AI systems fail, they generate incident data that can prevent future issues – but much of this data is lost or underutilized. Organizations face challenges like scattered logs, inconsistent incident descriptions, and privacy restrictions that hinder learning from past failures. Key insights include:
- GPU-related failures dominate (52.47% of incidents), but root causes are often unclear.
- Supervised learning works well for recurring problems but struggles with new issues.
- Unsupervised learning identifies hidden patterns but lacks precision in diagnostics.
- Anomaly detection helps catch outliers but generates false positives.
- NLP extracts insights from unstructured data like logs and chats but requires extensive cleaning.
Organizations like TUI reduced recovery times by 90% with automated response playbooks. Combining methods – like anomaly detection with NLP – can improve retraining processes and reduce incident costs, such as $1,700 per GPU-related failure. The goal is to create systems where every incident contributes actionable insights to refine AI models.
How to Safeguard Agentic AI: Lessons from SaaStr/Replit Production DB Deletion in Code Freeze Mode
1. Supervised Learning from Historical Incident Data
Supervised learning relies on labeled incident records to help identify and address similar issues in the future. Essentially, the model learns by analyzing examples where the root cause is already known, then applies those patterns to diagnose new problems. Between April 2023 and March 2024, Microsoft researchers studied around 1,300 real-world incident records from three production GPU clusters. They found that symptoms such as "invalid device ordinal" often pointed to deeper issues, like mismatched CUDA driver versions between Docker environments and virtual machines, rather than straightforward hardware failures.
Data Requirements
For supervised learning to work effectively, it needs well-structured data, including incident titles, detailed descriptions, error messages, system logs, root cause labels, on-call engineer discussions, and resolution steps. This data must be cleaned and standardized – removing irrelevant characters, trimming overly long stack traces, and summarizing lengthy descriptions – to focus on key symptoms and error codes. For example, the AI Incident Database (AIID) used a dataset of 815 AI incidents and 3,805 reports to test retrieval models. They found that including both the report title and full description improved ranking accuracy by 15% to 25% compared to using titles alone.
Detection Capability
Supervised models are excellent at spotting familiar patterns – incidents that have occurred before. A system like AidAI, trained on historical incident data, achieved a Micro F1 score of 0.854 in diagnosing AI workload incidents. GPU-related failures, which make up 52.47% of incidents in AI infrastructure, have a recurrence rate of 8.78, far higher than the 1.12 recurrence rate for framework-related issues. When patterns repeat, supervised learning reliably catches them.
However, these models struggle with new or unfamiliar incidents. For instance, one-shot root cause prediction systems like RCACopilot achieve only about 48% accuracy on AI workloads. As Stephen Grossberg aptly puts it:
Learning systems must remain stable enough to preserve what they know, yet be plastic enough to absorb new information.
Supervised learning prioritizes stability, which makes it less effective at identifying zero-day exploits or entirely new failure modes.
Implementation Complexity
One of the biggest hurdles is inconsistent incident descriptions – different users may describe the same root cause in vastly different ways, with varying levels of detail. To address this, organizations need to create a structured, hierarchical taxonomy (e.g., <main_category>.<sub_category>.<error_msg>) to label data for training. Transforming cleaned text into dense vector representations using tools like sentence transformers (such as all-mpnet-base-v2) enables semantic similarity tasks.
Another challenge is catastrophic forgetting – when retraining on new incidents, the model can overwrite previously learned information. To prevent this, replay buffers can be used to periodically reintroduce historical data during training. Techniques like Elastic Weight Consolidation (EWC) can also help by protecting weights important for past tasks, while still allowing the model to learn new incident types.
Scalability
Scaling supervised learning comes with its own set of challenges. For 64% of enterprise AI teams, the main bottleneck isn’t the number of GPUs but rather insufficient storage throughput. Paul Nashawaty, Principal Analyst at theCUBE Research, highlights this issue:
Organizations can scale multi-GPU clusters or distributed AI infrastructures without storage bottlenecks or architectural overhead.
At scale, manually linking new reports to historical incidents becomes unmanageable. Automation through semantic similarity is essential for maintaining large databases like the AIID. Privacy regulations, such as GDPR and HIPAA, add another layer of complexity – storing raw historical data for replay often violates these laws. Synthetic data generation offers a workaround, but it comes with its own set of challenges. On average, it takes 52.5 hours to resolve production incidents in large-scale AI infrastructures. For example, a single PCIe degradation failure in a 1,024-GPU task can waste over $1,700 in compute costs due to a 40-minute slowdown.
These limitations highlight the need for alternative approaches, which will be explored in the next sections on unsupervised learning and anomaly detection.
2. Unsupervised Learning for Pattern Discovery
Unsupervised learning is all about uncovering hidden patterns in data without needing predefined labels. This method plays a key role in advancing AI models that continuously learn and adapt from incident data. By analyzing unstructured data, it reveals connections that might otherwise go unnoticed by human analysts. This is especially useful when incident descriptions are inconsistent. For example, a single root cause category might have anywhere from 4.8 to 7.6 different descriptions across just ten incidents. Techniques like clustering based on cosine similarity are commonly used to group these varied descriptions under a shared underlying issue.
Data Requirements
The quality of data is crucial when it comes to identifying meaningful patterns. High levels of noise – like HTML tags, lengthy stack traces exceeding 10,000 tokens, or embedded images – can mislead models and result in incorrect conclusions. A two-step cleaning process helps here: first, stripping away irrelevant noise, and then summarizing the content to make it more manageable. Large datasets are particularly useful for spotting recurring issues, helping to distinguish isolated errors from systemic problems. Tools such as FAISS (a vector database) enable real-time similarity searches across historical incident data, making the process even more efficient.
Detection Capability
Unsupervised learning excels at spotting patterns that supervised models often miss. Between January 2021 and September 2022, Microsoft researchers analyzed 101,308 incidents across more than 1,000 services. They compared an unsupervised retrieval method with fine-tuned GPT-3 models. The results? The unsupervised approach outperformed supervised models by an average of 24.7% and showed a 49.7% improvement over zero-shot models. Incident owners also reported a 43.5% boost in the accuracy of detected patterns.
Xuchao Zhang from Microsoft highlights one of the main advantages:
The fine-tuned model struggles to address the issue of staleness, where emerging knowledge makes previous information obsolete.
This highlights why unsupervised learning is particularly effective in AI infrastructure. For example, a symptom like a CUDA error might not directly point to the root cause, such as a driver mismatch. While this approach delivers strong performance, it can come with challenges like reduced transparency and complex training dynamics.
Implementation Complexity
One of the toughest challenges in applying unsupervised learning is managing the balance between stability and adaptability – known as the stability–plasticity dilemma. Models need to retain existing knowledge while staying flexible enough to learn new patterns. Techniques like replay buffers and Elastic Weight Consolidation help mitigate "catastrophic forgetting" as datasets evolve.
Another hurdle is the "black box" nature of many unsupervised models, which makes it hard to understand why certain anomalies are flagged. Even though AI-driven alert correlation can reduce noise by up to 80%, poorly calibrated systems might still generate too many false alarms, leading to alert fatigue.
Scalability
Unsupervised learning offers better scalability than supervised methods because it doesn’t rely on constant retraining with labeled data. However, maintaining these models can be resource-intensive, requiring robust memory buffers and complex architectures. In real-world settings, the median time to resolve AI incidents is 52.5 hours, and service outages can cost companies over $100,000 per hour.
To address scalability challenges, organizations should start small – perhaps with pilot projects like alert deduplication or automated classification – before moving on to more advanced tasks like autonomous remediation. Implementing strong MLOps practices, such as drift monitoring, version control, and automated updates, is essential for managing the lifecycle of these continuously learning models. Up next, we’ll look at how anomaly detection can further refine baseline models, pushing continuous learning even further.
3. Anomaly Detection and Baseline Refinement
Anomaly detection plays a crucial role in identifying unexpected deviations from normal behavior by using dynamic thresholds that adapt alongside your infrastructure. Unlike methods that group similar patterns, anomaly detection focuses on setting flexible benchmarks to detect outliers as systems evolve. This approach fine-tunes baseline models, catching deviations that traditional techniques might miss. It also lays the groundwork for exploring the data requirements and detection capabilities essential for effective monitoring.
Data Requirements
To implement anomaly detection in AI workloads, you need a comprehensive set of metrics. This includes hardware telemetry – tracking GPU ECC errors, PCIe degradation, and InfiniBand interconnect health – since these components are among the most failure-prone in production AI systems. Equally important is cross-lifecycle data, which integrates details from code, configurations, service properties, and dependencies throughout the software development lifecycle.
Monitor metadata adds essential context for setting accurate thresholds. By categorizing monitors based on resource types (API, CPU, Storage) and Service Level Objective classes (e.g., Latency, Availability, Throughput), systems can better prioritize deviations that matter most. Additionally, capturing "near harm" data – potential issues that haven’t yet caused failures – enables proactive adjustments to baselines before problems escalate into customer-facing incidents.
Detection Capability
Effective anomaly detection can prevent cascading failures. For example, a single PCIe degradation in a task involving 1,024 GPUs could delay processes by 40 minutes, incurring costs of over $1,700. Companies like TUI have reduced service recovery times by up to 90% by leveraging response playbooks that feed incident data into automation systems.
Microsoft’s Argos system exemplifies modern advancements in detection. Instead of relying on costly runtime inference, Argos uses large language models (LLMs) during training to generate deterministic, executable rules. This approach improved F1 scores by up to 28.3% on internal datasets and accelerated inference speeds by 1.5x to 34.3x across various datasets. By combining Detection, Repair, and Review agents, Argos continuously refines its rules, enhancing performance while maintaining explainability – an area where traditional deep learning models often fall short.
Implementation Complexity
Balancing historical data with new inputs presents a challenge often referred to as the stability-plasticity dilemma. While AI-powered systems can cut alert noise by as much as 80%, poorly calibrated models risk generating excessive false positives, leading to alert fatigue for on-call engineers.
Data quality further complicates implementation. For instance, the Argos team discovered a 4.8% syntax error rate in initial LLM-generated code, necessitating automated repair agents within the pipeline. As the Argos team highlights:
An autonomous anomaly detection system can adapt to these changes in data distribution without any human intervention.
This level of autonomy is critical but requires robust validation loops. Systems must verify anomalies by cross-checking actual GPU status to minimize false positives, especially in high-volume environments. Addressing these challenges is key to building scalable solutions for dynamic systems.
Scalability
Scalability becomes a pressing issue when monitoring thousands of services simultaneously. Traditional deep learning methods often fall short in real-time scenarios due to the computational expense of hyperparameter tuning. The AWS outage in December 2021, which lasted over 10 hours and disrupted millions of users, underscores the risks of monitoring systems failing to scale during unexpected infrastructure changes.
For AI workloads, the stakes are even higher. Service failures can cost medium and large enterprises over $100,000 per hour, making scalable anomaly detection a financial necessity. Start small with targeted use cases like alert deduplication, then expand to more complex scenarios. Your system must also adapt autonomously, generating new rules as data patterns evolve.
sbb-itb-f9e5962
4. Natural Language Processing for Unstructured Data
While structured methods handle defined metrics, Natural Language Processing (NLP) opens the door to insights buried in unstructured data, completing the feedback loop for continuous learning. By analyzing unstructured incident data – like summaries and chat logs – NLP captures the "tribal knowledge" engineers rely on to diagnose problems. This type of data, often overlooked by structured approaches, holds invaluable insights. However, extracting meaningful patterns requires careful pre-processing and summarization.
Data Requirements
NLP systems thrive on diverse unstructured inputs, such as titles, summaries, logs, chat histories, reviews, and support tickets. But there’s more to it. Adding context from across the lifecycle – like service architecture details, upstream dependency functions, and monitoring metadata – can significantly boost diagnostic precision.
The quality of raw incident data is critical. Elements like HTML tags, stack traces, and even images can overwhelm token limits and lead to errors. A two-step approach works well: first, local scripts clean up the data by removing unnecessary noise; then, a smaller model (e.g., GPT-3.5-turbo) summarizes verbose logs before passing them to larger models. Between January 2023 and January 2024, Microsoft’s IC3 service tested this method on 353 high-impact incidents. They found that including upstream dependency descriptions in incident metadata significantly improved the accuracy of root cause recommendations.
Detection Capability
Traditional one-shot NLP models, which directly map incident descriptions to root causes, often fall short in complex AI environments. For example, GPU-related failures account for 52.47% of AI workload incidents, with a recurrence rate of 8.78%, even though each incident is described differently in unstructured reports.
Multi-step reasoning systems perform much better. Researchers evaluated AidAI between April 2023 and March 2024 using around 1,300 incident records from three production GPU clusters. By imitating how on-call engineers diagnose issues – using taxonomy-guided reasoning – the system achieved a Micro F1 score of 0.854. Yitao Yang and colleagues from The Chinese University of Hong Kong highlighted the challenges of bridging knowledge gaps between customers and providers:
The inherent knowledge gap between customer and provider significantly impacts incident resolution efficiency.
Detection systems improve further through a continuous operations loop, where every incident, from detection to resolution, feeds back into the AI system. PagerDuty emphasizes this concept, and its effectiveness is evident: in December 2025, TUI, a global travel company, reduced service recovery times by up to 90% across its network by adopting this approach. This underscores the importance of robust data pipelines, which we’ll explore in the implementation section.
Implementation Complexity
Implementing NLP for incident data requires a layered architecture for ingestion, processing, orchestration, and specialized storage. A Microsoft study involving over 40,000 incidents showed that fine-tuned large language models can effectively support on-call engineers with root cause analysis – but only with significant infrastructure support.
Enhancing monitor categorization with additional service and component data increased accuracy and F1 scores by 4%, but only after thorough data cleaning. Retrieval-Augmented Generation (RAG), which pulls the top five similar historical incidents from a vector database, also provides valuable context for models. As Drishti Goel of Microsoft noted:
Existing research typically takes a silo-ed view for solving a certain task in incident management by leveraging data from a single stage of SDLC.
Large language models often struggle with domain-specific nuances, requiring manual curation into internal knowledge bases. This highlights the ongoing need for human-in-the-loop evaluations to ensure model outputs align with real-world needs.
Scalability
Scaling NLP systems comes with its own set of challenges, particularly in managing infrastructure. A tiered storage setup – combining vector databases for semantic search, document stores for detailed reports, and time-series databases for metrics – can streamline operations.
Organizations often start small, focusing on specific use cases like automated root cause recommendations. Over time, they can expand into more complex areas, such as customer-centric diagnosis, reducing the diagnostic workload for infrastructure providers. By scaling thoughtfully, teams can unlock the full potential of NLP for unstructured data.
Pros and Cons of Each Approach
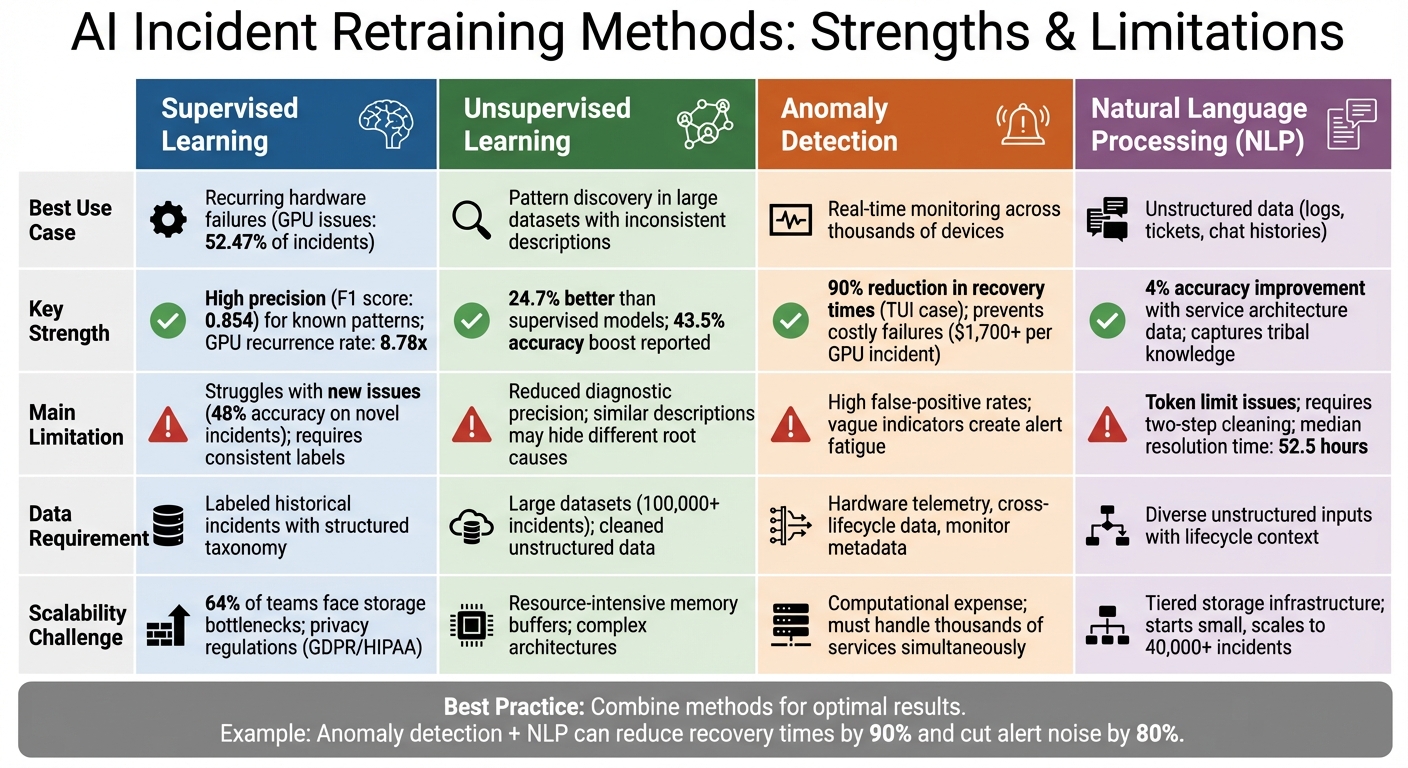
Comparison of AI Incident Retraining Methods: Supervised, Unsupervised, Anomaly Detection, and NLP
Now that we’ve explored the specifics of each retraining method, let’s break down their strengths and limitations when it comes to continuous learning.
Supervised Learning is particularly effective at pinpointing specific causes of recurring hardware failures, especially GPU-related issues, which make up 52.47% of AI workload incidents. However, it struggles in more complex scenarios due to limited intermediate reasoning. It also depends heavily on consistent historical labels, which can be a challenge when engineers provide inconsistent levels of detail. This reliance on past data can hinder the system’s ability to adapt to new or unexpected failure modes, posing a direct challenge to continuous learning.
Unsupervised Learning thrives on large datasets, grouping similar incident variants to uncover systemic issues. However, it can fall short when similar descriptions hide different root causes. As Kevin Paeth put it, these systems need to "embrace methodologies and cultures that are conducive to investigation in the presence of uncertainty". While the absence of predefined labels allows for broader pattern discovery, it comes at the cost of reduced diagnostic precision, which can slow continuous improvement efforts.
Anomaly Detection is well-suited for real-time monitoring across thousands of devices, making it a great tool for refining baselines. But it has its downsides – high false-positive rates and vague indicators often leave engineers sifting through noise rather than actionable data. This can overwhelm teams and detract from the system’s ability to learn and improve over time.
Natural Language Processing (NLP) shines when dealing with unstructured data like logs and support tickets, as it doesn’t rely on rigid templates. Enhancing NLP models with service architecture data has been shown to improve classification accuracy by 4%. Yet, NLP faces its own challenges, such as token limit exhaustion and noise, which often require a two-step cleaning process to reduce errors like hallucinations. Despite these advancements, the median time to resolve AI infrastructure incidents is still 52.5 hours, highlighting the need for more efficient diagnostic tools.
A combined approach could address these individual weaknesses. For example, using anomaly detection to flag issues and NLP to extract meaningful context could speed up the retraining process and drive continuous improvement.
Conclusion
Selecting the right retraining strategy hinges on factors like data quality, system complexity, and operational scale. For routine software issues where symptoms clearly lead to root causes, supervised learning with historical labels can be effective – provided your incident documentation is thorough and consistent. On the other hand, for hardware-software interactions, such as costly PCIe degradation scenarios, taxonomy-guided approaches align better with how engineers naturally troubleshoot.
Scaling is another key consideration. Large organizations handling over 40,000 incidents annually may find it worthwhile to invest in fine-tuned large language models (LLMs) for extensive automation. Smaller teams, however, should focus on targeted anomaly detection, expanding only when specific use cases prove successful. Starting with small-scale pilots and validating results through data-driven insights ensures a solid foundation before committing to broader automation initiatives.
The most impactful results often come from combining multiple methods. For instance, anomaly detection can flag early warning signs, natural language processing (NLP) can extract context from unstructured logs, and taxonomy-guided reasoning can handle intricate diagnostic challenges. A great example of this is TUI, which managed to cut recovery times by up to 90% by integrating automated response playbooks into a continuous operations framework. This underscores an essential point: the goal isn’t to find one "perfect" method but to create a system where every incident contributes structured data to refine your training pipeline.
As David Williams from PagerDuty insightfully pointed out:
Most incident processes forget what happened as soon as the issue is closed… responders start from scratch, relying solely on tribal knowledge. – David Williams, PagerDuty
FAQs
How can businesses use AI incident data to improve model retraining?
To improve model retraining, businesses can dive into AI incident data to uncover patterns linked to performance issues or model drift. By reviewing past incidents, they can identify when models start straying from expected behavior, signaling the need for updates. Creating internal knowledge bases from this information simplifies troubleshooting and ensures retraining efforts are focused and effective.
Keeping a close eye on performance metrics and incident logs helps catch anomalies early, allowing for timely retraining. Integrating incident data into continuous learning workflows also supports automated or step-by-step updates, ensuring models stay accurate and in sync with changing data environments. This method not only boosts AI reliability but also reduces downtime and keeps systems running smoothly.
What challenges arise when using unsupervised learning for managing AI incidents?
Implementing unsupervised learning in managing AI incidents presents a few hurdles. One major obstacle is the absence of labeled data, making it tough to identify and classify incidents accurately. This can lead to either misclassifications or, worse, missing critical detections altogether. On top of that, these models often find it difficult to adapt to the constantly shifting patterns of incidents, particularly in fast-changing environments like cloud systems or AI workloads. The result? A higher risk of false positives or missed issues.
Scalability is another sticking point. Processing large datasets demands significant computational power, which can strain resources. Plus, without labeled data, validating and interpreting the model’s outputs becomes more challenging. This lack of clarity can erode trust in the system and slow down decision-making for incident response teams.
To overcome these issues, unsupervised learning needs to be thoughtfully woven into a broader incident management strategy. When done right, this approach can help ensure the insights generated are both accurate and actionable.
How does anomaly detection improve AI system monitoring and prevent incidents?
Anomaly detection plays a crucial role in monitoring AI systems by spotting unusual patterns or behaviors that might indicate potential problems. By catching these irregularities early, teams can tackle issues before they snowball into major disruptions.
Through constant data analysis, anomaly detection not only helps maintain the reliability of AI systems but also boosts their performance and enables proactive decision-making. It’s an essential tool for keeping AI systems running smoothly and efficiently in the long run.