How AIOps Enables Self-Healing Infrastructure

AIOps is transforming IT operations by automating problem detection, diagnosis, and resolution. Self-healing infrastructure leverages AIOps to minimize downtime, reduce manual intervention, and improve system reliability. Here’s what you need to know:
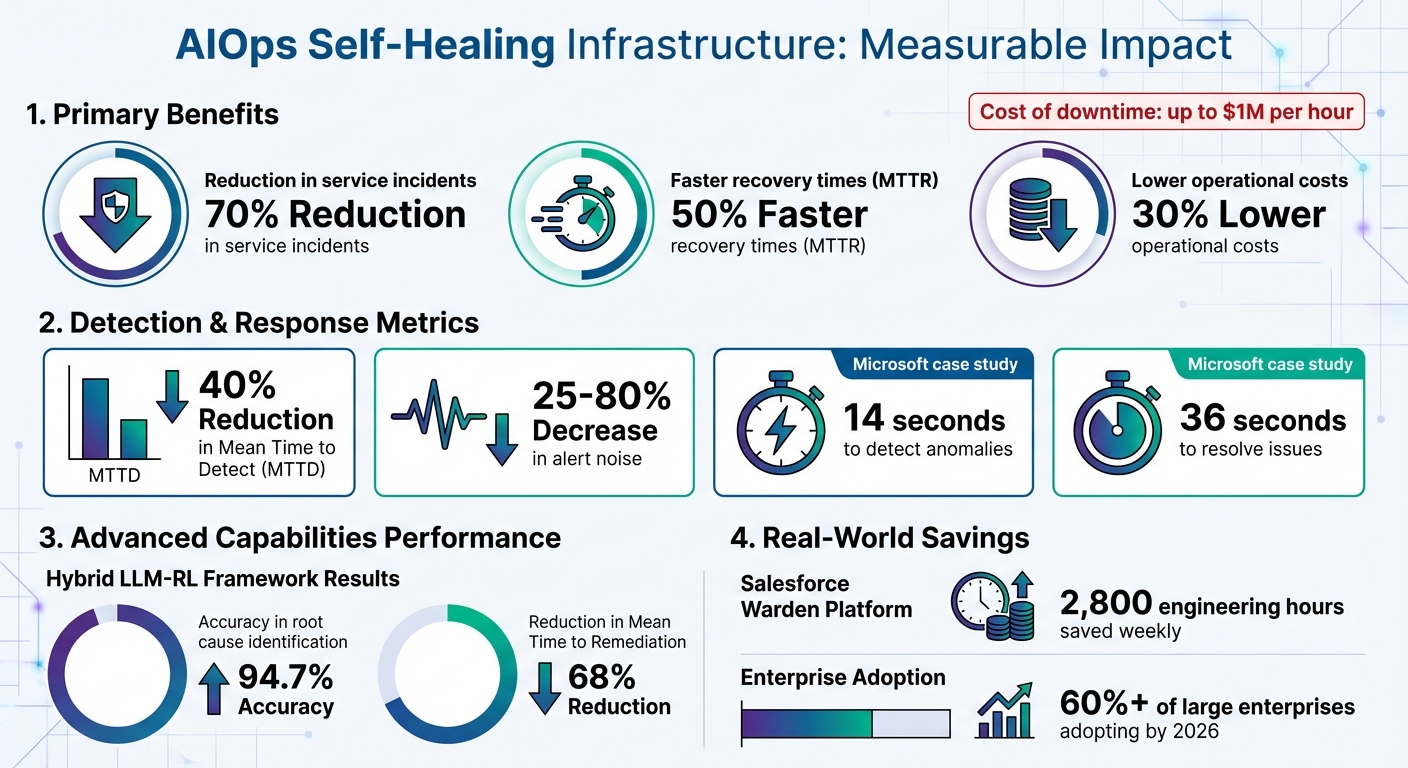
- Key Benefits: Organizations report up to a 70% drop in service incidents, 50% faster recovery times, and 30% lower operational costs.
- Core Functions: AIOps processes metrics, events, logs, and traces to detect anomalies, identify root causes, predict failures, and execute automated fixes.
- Real-World Impact: Examples include cutting alert noise by 80%, reducing detection time by 40%, and saving thousands of engineering hours weekly.
AIOps is already delivering measurable results, making it a game-changer for IT teams managing complex systems. By starting small – like automating basic tasks – companies can steadily implement self-healing capabilities without overhauling their infrastructure.
AIOps Self-Healing Infrastructure: Key Benefits and Performance Metrics
Autonomous cloud infrastructure: AI-driven self-healing and optimization – Faiz Gouri
How AIOps Enables Self-Healing
Self-healing infrastructure depends on three key abilities that work together to keep systems functioning without manual intervention. AIOps platforms process MELT data – metrics, events, logs, and traces – across infrastructure, applications, and networks to establish performance benchmarks. Using these benchmarks, machine learning models identify issues, predict potential failures, and implement fixes. These capabilities form the backbone of anomaly detection, incident prevention, and rapid recovery.
Anomaly Detection and Root Cause Analysis
AIOps leverages machine learning to detect unusual system behavior in real time by spotting deviations from expected patterns. Advanced platforms go a step further, employing Graph Neural Networks (GNNs) to understand the relationships between various services and nodes. This approach consolidates multiple alerts into a single actionable incident, significantly reducing the noise that overwhelms IT teams. In fact, this method can cut alert noise by 25% to 80%.
Causal inference plays a critical role in identifying root causes before issues escalate. For example, in 2025, IBM Research showcased its AIOps Insights platform, which detected a 5% performance slowdown in a Redis data storage application. Using causal analysis, the AI pinpointed "CPU cache thrashing" as the culprit. It then utilized a large language model to create a Kubernetes script that isolated the faulty node and restored the Redis pods, preventing a major workload failure. This closed-loop remediation process follows four steps: Detect, Diagnose, Decide, and Act.
Predictive Analytics for Incident Prevention
Predictive analytics helps anticipate failures before they occur. By examining historical data and system dependencies, AIOps platforms identify early warning signs of potential issues. This capability is especially valuable since roughly 60% of IT incidents stem from non-code problems, such as infrastructure or service dependencies. Predictive detection can reduce Mean Time to Detect (MTTD) by 40%. Additionally, advanced AI agents assess the potential impact of predicted failures, enabling teams to prioritize fixes based on the severity of the issue.
Padraig Byrne, Senior Director Analyst at Gartner, highlights the importance of this shift:
"The ability to automatically detect, diagnose, and remediate incidents will be the most transformative shift in IT operations over the next five years".
Once potential issues are flagged, automated systems step in to restore stability quickly and efficiently.
Automated Remediation for Faster Recovery
When problems arise, AIOps platforms take action immediately, implementing solutions like restarting services, rerouting traffic, or scaling resources – all without waiting for human input. Modern systems treat runbooks as version-controlled code, ensuring consistent and repeatable responses. If no pre-defined playbook exists, large language models analyze the situation and generate custom scripts suited to the specific environment. This phase completes the self-healing cycle initiated by earlier detection and prediction.
Closed-loop remediation can slash Mean Time to Recovery (MTTR) by an average of 50%. For instance, in 2024, Microsoft researchers tested a ReAct agent powered by GPT-4 on a SocialNetwork microservices application. After introducing a virtualization-layer misconfiguration, the AIOps agent identified the anomaly in just 14 seconds and resolved the issue in 36 seconds by correcting the misconfigured port. This rapid response is crucial, especially when unplanned downtime can cost businesses up to $1 million per hour.
Research and Studies on AIOps Self-Healing
Recent research highlights the growing role of autonomous, self-healing systems within the realm of AIOps, building on its predictive and automated remediation capabilities.
Findings on Predictive Incident Management
The evolution from reactive troubleshooting to predictive, autonomous systems is evident in recent studies. These systems leverage machine learning and reinforcement learning to identify and address issues. Hybrid frameworks are now a focal point, combining large language models (LLMs) for log analysis and root cause identification with reinforcement learning (RL) to execute remediation policies automatically.
In 2025, researcher Manav Sutar tested a hybrid LLM-RL framework across 500 real-world failure scenarios. The results were impressive: the system achieved 94.7% accuracy in identifying root causes and reduced Mean Time to Remediation (MTTR) by 68% compared to manual debugging. For instance, in the "Payment Service Crashloopbackoff" scenario, the framework employed a context-aware LLM agent alongside an RL-based remediation engine. This combination identified the root cause and executed a GitOps-integrated safe deployment workflow, effectively resolving complex Kubernetes failures without human intervention.
Another study by Microsoft researchers, conducted between April and June 2025, analyzed 156 high-severity incidents in a production LLM serving environment. Their findings showed that 74% of incidents were auto-detected by health probes and AIOps pipelines, though 28% still required manual intervention. To address this, the team implemented GPU capacity-aware routing and connection liveness strategies, which significantly reduced HTTP 408 error rates and improved compliance with service level agreements. These advancements highlight the potential for real-world applications, as demonstrated in the following case studies.
Self-Healing Case Studies
Jim Kleewein, Technical Fellow at Microsoft 365, underscored the importance of autonomous systems in maintaining service reliability:
"One important aspect of achieving continuous availability and highly reliable services is to understand incidents holistically and mitigate their impact to customers".
Kleewein’s team studied 40,000 incidents and found that fine-tuning GPT-3.5 with specific incident data enhanced mitigation generation tasks by 131.3% compared to zero-shot settings. The research also revealed that while 60% of cloud incidents originate from non-code issues in infrastructure and deployment, 80% of code-related incidents can be addressed without requiring a code fix, thanks to AIOps-driven actions.
These findings illustrate the transformative potential of self-healing systems in managing and mitigating incidents efficiently.
sbb-itb-f9e5962
Comparison of AIOps Self-Healing Approaches
Self-healing infrastructure uses various AIOps strategies, each offering distinct strengths and challenges. Choosing the right approach depends on an organization’s operational readiness and risk tolerance. Below, we break down the main methodologies, their benefits, and their trade-offs.
Predictive Analytics focuses on spotting potential issues before they escalate. By leveraging machine learning to uncover anomalies and patterns, this method significantly cuts detection time and reduces alert fatigue. It aligns well with the self-healing model by supporting swift recovery and cutting downtime. However, its effectiveness hinges on high-quality data, and there’s always a risk of false positives, which can undermine trust within teams.
Automated Remediation relies on closed-loop systems to execute predefined playbooks without human input. This approach has shown measurable results, with some organizations achieving up to a 50% reduction in Mean Time to Resolution (MTTR). Bernd Greifeneder, CTO and Founder of Dynatrace, highlighted its impact:
"AI-driven remediation is no longer a theory. Customers are already seeing measurable drops in MTTR and alert fatigue when machine learning is applied responsibly".
While this method enhances recovery speed and reduces downtime, it requires careful oversight to avoid "automation drift", where unintended consequences arise from automated actions. Strict policy enforcement is essential to mitigate these risks.
Reinforcement Learning takes automation to the next level by using adaptive feedback loops to refine accuracy over time. These systems boast over 90% accuracy and have demonstrated impressive speed in practical applications. However, Gartner predicts that more than 40% of initiatives using this approach may fail by 2027 due to issues like trust deficits and unclear returns on investment. Despite its potential, this method demands significant complexity and ongoing human oversight.
Comparative Analysis Table
The following table highlights the key distinctions and benefits of each AIOps approach:
| Approach | Key Mechanisms | Supporting Studies | Advantages | Limitations |
|---|---|---|---|---|
| Predictive Analytics | Machine learning for anomaly detection and causal inference | Splunk State of Observability 2024; Gartner 2025 | Prevents incidents proactively; 22% higher SLO adherence; 40% reduction in MTTD | Requires high-quality data; risk of false positives |
| Automated Remediation | Closed-loop systems; Runbooks-as-Code | Dynatrace Davis AI Case Study 2025; ServiceNow 2025 | Cuts MTTR by 50%; reduces alert noise by 80%; ensures consistent recovery | Risk of automation drift; demands strict policy guardrails |
| Reinforcement Learning | Adaptive feedback loops; agent-based automation | Gartner Agentic AI Report 2025/2026; Microsoft AIOpsLab 2024 | Learns from feedback; >90% accuracy; rapid issue resolution | High complexity; 40% failure rate predicted; needs human-in-the-loop training |
Future of AIOps and Self-Healing Infrastructure
Trends in Autonomous IT Operations
The evolution of AIOps is moving beyond simple problem detection to systems capable of autonomous diagnosis and repair. This marks a major departure from traditional monitoring tools, which merely alert human operators, toward intelligent systems that act independently within pre-set boundaries.
One key advancement is closed-loop remediation, now a standard approach that ensures smoother operations. By 2026, over 60% of large enterprises are projected to adopt these self-healing systems, driven by the staggering cost of downtime – estimated at $9,000 per minute on average.
Self-healing systems are also being reshaped by integration with zero-trust security models. AIOps now automates the "never trust, always verify" principle by continuously scanning networks and validating configurations in real time. When unusual behavior is detected, machine learning models step in to dynamically adjust permissions, isolate compromised systems, and block lateral threats. This ensures a secure foundation for self-healing workflows, creating a protective layer between IT and network systems.
Another critical development is OpenTelemetry 2.0, which provides the unified data framework necessary for accurate root-cause analysis. By standardizing log and trace correlation, it strengthens system performance and reliability. Meanwhile, the convergence of IT and Operational Technology (OT) is expanding AIOps beyond traditional data centers into environments like factories, retail spaces, and edge locations.
These advancements are paving the way for significant improvements in both cost efficiency and system performance.
Cost and Performance Optimization Opportunities
Building on these autonomous capabilities, AIOps is also driving smarter resource use and lowering operational expenses. Through adaptive automation, these platforms integrate FinOps practices to track Kubernetes and cloud usage, identify over-provisioning, and prioritize resource optimization.
A notable example comes from Salesforce, which, in November 2025, showcased its internal "Warden" platform. Designed under the leadership of EVP of Engineering Paul Constantinides, this system leverages the Merlion and Moirai libraries to proactively detect, diagnose, and resolve issues. The result? A weekly savings of 2,800 engineering hours. This efficiency allows site reliability teams to focus on strategic projects rather than constant monitoring.
Another cost-saving measure is the use of observability pipelines, which filter out unnecessary data before it reaches expensive analytics tools. This addresses a common challenge: managing the overwhelming volume of telemetry data. In fact, 85% of IT leaders identify this as a critical issue, with over half of traditional alerts proving to be false positives or redundant notifications.
Predictive capacity management is another area of impact. By analyzing historical trends, these systems forecast potential capacity shortages or hardware failures, enabling proactive scaling and maintenance. For instance, a global financial services firm implemented real-time anomaly detection and automated root-cause correction in 2025, reducing downtime by 45% within six months and significantly improving customer satisfaction.
As one expert aptly put it:
"Self-healing doesn’t replace engineers – it scales their intent across infrastructure." – AI Competence
Conclusion
AIOps is transforming how IT teams handle infrastructure, shifting the focus from reactive problem-solving to proactive management. By enabling systems to detect issues, pinpoint root causes, and resolve them automatically, it offers a smarter, more efficient way to maintain operations. For small to mid-sized SaaS and AI companies, this is a game-changer. It ensures reliable, 24/7 operations without the need to significantly expand engineering teams.
The results speak for themselves: organizations adopting AIOps report a 50% reduction in Mean Time to Recovery (MTTR), a 30% cut in operational costs, and a 25% to 80% decrease in alert noise. These numbers highlight a major shift in how systems are managed, offering clear benefits for those ready to embrace the change.
Getting started with AIOps doesn’t require overhauling your entire infrastructure. Start small and focus on low-risk workflows like clearing caches, restarting nodes, or scaling resources. From there, you can gradually implement automation for more critical tasks. A key step is centralizing telemetry using standards like OpenTelemetry. This creates a strong data foundation for AI models and enables automated remediation through runbooks.
No longer just a concept, AIOps is already delivering real results in production environments. Self-healing infrastructure extends the reach of engineering teams, scaling their efforts across systems without replacing their expertise.
FAQs
How does AIOps enhance system reliability and minimize downtime?
AIOps takes system reliability to the next level by processing massive amounts of data – like logs, metrics, and events – using machine learning. This enables it to spot anomalies and predict potential failures before they cause major disruptions. With this proactive approach, IT teams can tackle issues early, or even let the system resolve problems on its own through self-healing capabilities. Features like predictive monitoring and automated root-cause analysis mean problems are identified and fixed much faster, ensuring quicker and more efficient responses overall.
When something does go wrong, AIOps platforms can automatically execute pre-set actions to fix the issue, verify that the system is back to normal, and completely remove the need for manual troubleshooting. This not only minimizes downtime but also ensures businesses can maintain high service availability – critical for demanding sectors like healthcare and finance. By leveraging these tools, TECHVZERO helps businesses cut operational costs, boost performance, and keep their infrastructure reliable and scalable with AIOps-driven automation.
How does machine learning enable self-healing in AIOps infrastructure?
Machine learning (ML) is a game-changer for creating self-healing infrastructure within AIOps. By processing massive amounts of data – like logs, metrics, and system events – ML models uncover patterns tied to recurring issues and spot anomalies that could indicate trouble. These models can even predict failures before they happen, triggering automated fixes such as restarting services, reallocating resources, or tweaking configurations. The result? Smooth operations with minimal interruptions.
At TECHVZERO, we’ve built ML-powered AIOps right into our DevOps and cloud optimization tools. Our systems continuously learn from customer data, enabling real-time outage predictions and automatic self-healing responses. This not only reduces downtime and speeds up recovery but also cuts operational costs, ensuring businesses across the U.S. have dependable and scalable infrastructure.
How can organizations implement AIOps to create a self-healing infrastructure?
To set up AIOps for a self-healing infrastructure, the first step is to build a solid observability framework. This involves collecting data from various sources – logs, metrics, traces, and events – spanning servers, containers, cloud services, and network devices. All this data should be fed into a unified monitoring platform that delivers real-time analytics. This gives the AI system the context it needs to spot anomalies and anticipate potential issues before they escalate.
The next step is to establish clear remediation policies and workflows. The AI system should be configured to identify unusual patterns, determine root causes, and automatically carry out pre-approved corrective actions without the need for manual input. Start with a pilot program targeting a non-critical service to test the model’s reliability. Once validated, you can gradually implement it across other systems to achieve consistent and measurable outcomes.
For those looking for specialized assistance, TECHVZERO offers comprehensive AIOps solutions. Their services include data engineering for actionable insights, automated deployment pipelines, and AI-driven incident resolution. By leveraging their expertise, businesses can minimize downtime, lower operational costs, and speed up deployments, all while creating a dependable self-healing infrastructure.