Dependency Mapping: Multi-Cloud Best Practices

Dependency mapping is key to managing multi-cloud environments like AWS, Azure, and Google Cloud. It identifies how systems interact and where dependencies exist, helping prevent failures from cascading across your infrastructure. The article outlines four main approaches to dependency mapping:
- Manual Mapping: Relies on tools like spreadsheets or diagrams. It’s outdated quickly and ineffective for dynamic systems.
- Network Analysis: Tracks network traffic to map dependencies in real-time. It’s faster but can miss application-level details.
- Application Tracing: Uses tools like OpenTelemetry to monitor service interactions. Provides detailed visibility but requires significant setup.
- IaC Mapping: Extracts dependencies from infrastructure code (e.g., Terraform). It’s automated and scales well but may overlook manual changes.
Each method has strengths and limitations, making a combined approach ideal. Automating dependency tracking, integrating tools into CI/CD pipelines, and focusing on critical areas can reduce outages and improve system reliability.
Application Dependency Mapping in a Multi-Cloud deployment
1. Manual and Diagram-Driven Mapping
Manual mapping relies on tools like spreadsheets or diagram software, such as Microsoft Visio, to document how components interact. While this approach might work for simpler systems, it quickly falls short in dynamic, multi-cloud environments. These setups evolve constantly, making manual methods ineffective for keeping up with the pace of change.
Coverage and Freshness
The biggest flaw of manual maps? They’re static. In fast-changing multi-cloud environments, where CI/CD pipelines can alter dependencies multiple times a day, static maps are outdated almost as soon as they’re created. In fact, 56% of enterprises report incomplete views of dependencies when relying on non-automated methods. This lack of up-to-date visibility makes tracking dependencies in real-time operations a daunting task.
Operational Complexity
Manually identifying dependencies isn’t just tedious – it’s a gamble. IBM describes it as a "lengthy, time-consuming process with no guarantee that IT team members will emerge with a complete understanding of a system’s complexity". The constant changes in dependencies mean teams are always playing catch-up. Add to that the fact that only 9% of technologists report having extensive experience across cloud platforms like AWS, Azure, and Google Cloud, and the challenge becomes even more overwhelming.
Scalability and Suitability for Multi-Cloud
Manual mapping struggles the most in multi-cloud environments, especially when dealing with resources that are here one moment and gone the next. For example, Kubernetes pods can spin up and down in seconds, and SaaS-to-SaaS integrations often rely on hidden API keys – both of which manual methods fail to capture reliably. Cloudaware puts it bluntly:
Don’t even think about manually tracking your CIs and dependencies. In 2025, that’s a recipe for disaster.
The statistics paint a grim picture: 53% of enterprises face challenges with server consolidation due to the limited visibility of manual mapping, and 75% of dependency vulnerability patches end up breaking systems because hidden relationships weren’t accounted for. It’s clear that manual mapping simply can’t keep pace with the demands of modern cloud infrastructures.
2. Network-Centric Discovery and Flow Analysis
Network-centric discovery works by intercepting network traffic to map out system dependencies. Instead of relying on outdated documentation or manual tracking, these tools monitor network calls to gather insights like TCP flow and DNS activity. They can also pinpoint communication patterns – such as API calls and database queries – giving a clear picture of how systems interact.
Coverage and Freshness
The difference in speed is striking. Manual discovery methods can take weeks to gather and merge data, while network-centric tools can capture and report most dependencies in just a few days. These tools consolidate data from sources like VPC Flow Logs, NetFlow records, and SNMP/API metrics into a single, topology-aware view. This real-time tracking eliminates the delays caused by manual documentation. However, fragmented environments can make real-time monitoring more challenging.
Operational Complexity
Even though network-centric tools quickly update dependencies, managing fragmented monitoring across multiple clouds introduces complications. With over 65% of organizations now working in multi-cloud environments, the lack of cross-cloud expertise often makes operations more difficult. Using separate monitoring tools for different cloud providers leads to incomplete views, and inconsistent security policies require manual efforts to identify gaps. Drew Firment, VP of Enterprise Strategy at Pluralsight, highlights this issue:
Lack of education is a main contributor to the accidental multicloud environment and can contribute to disparate architectures.
Centralizing visibility can address these issues. Tools like Google’s Network Intelligence Center and AWS Network Monitor provide a unified interface for troubleshooting across environments. Additionally, using service meshes with features like mTLS and SNI-based routing can secure cross-cloud communications without requiring teams to become experts in each platform’s intricacies.
Scalability and Suitability for Multi-Cloud
Network-centric discovery scales well because it works directly at the infrastructure level. Modern tools using eBPF technology (like Pixie or Cilium) offer kernel-level visibility into service communications without requiring code changes. This makes them especially useful for large microservice architectures. These tools also provide detailed cost breakdowns by availability zones, regions, and egress traffic. Companies leveraging advanced dependency mapping have reported a 32% drop in change failure rates and a 47% improvement in Mean Time to Recovery during complex incidents. However, one limitation remains: while network metrics can show what changed, they still need to be paired with log data to understand why.
3. Application-Centric and Tracing-Based Mapping
Application-centric mapping focuses on tracking how requests move between services, databases, and APIs. Instead of analyzing network packets, this method instruments your code to monitor how applications interact during runtime. Tools like OpenTelemetry libraries or eBPF-based solutions (e.g., Pixie, Cilium) are commonly used to trace services across different programming languages. These dependency maps automatically update with each traced request, evolving in step with your infrastructure.
Coverage and Freshness
One of the key advantages of this approach is its ability to update dependency maps in real time. Universal Service Monitoring (USM) can identify all active services in your architecture, including undocumented or shadow IT components that manual methods often overlook. By integrating with CI/CD pipelines, these maps can refresh as soon as new services are deployed, eliminating the delays associated with manual documentation. However, incomplete instrumentation may leave gaps in visibility – often referred to as the "missing 20%". Despite this, organizations that have implemented mature tracing solutions report tangible benefits, such as a 53% increase in successful first-time service migrations and a 28% reduction in onboarding time for new team members. This real-time accuracy is especially valuable for navigating complex and dynamic environments.
Operational Complexity
Although this approach provides real-time insights, it requires careful integration with existing CI/CD systems. Rolling out application-centric mapping typically involves deploying agents or integrating OpenTelemetry across your codebase, which can demand significant developer effort. Service meshes like Istio offer an alternative by capturing traffic transparently, though they come with added infrastructure overhead. Multi-cloud environments introduce additional challenges, as native monitoring tools from different providers often present siloed views. Adopting OpenTelemetry as a vendor-neutral standard can help unify telemetry across clouds. Jamie Rossato, Chief Information Security Officer at Lion, highlighted the immediate advantages of such visibility:
We started seeing benefits from Illumio right away. We gained visibility into our environment and took decisive action immediately… Illumio allowed us to take a step-by-step approach and realize value out of the gate.
Cost Efficiency
Tracing does come with costs. Organizations typically allocate 10% to 12% of their total cloud budget to observability services. Tracing adds extra overhead, not only in terms of compute resources for instrumentation but also in data egress costs when centralizing telemetry across cloud environments. To manage costs in high-load scenarios, adjusting trace sampling rates (e.g., reducing to 50%) can help strike a balance between visibility and expenses.
Scalability and Suitability for Multi-Cloud
Application-centric mapping improves multi-cloud visibility by incorporating business context and metadata, such as ownership details and service-level agreements. This approach scales well by combining technical connections with contextual insights, including protocol-aware analysis for HTTP, gRPC, and Kafka. Major cloud providers like Amazon have used real-time graph models of microservice dependencies since as early as 2008 to manage complexity. For scenarios where modifying code isn’t feasible, eBPF-based tools offer a practical alternative. A phased approach is often the most effective – start by mapping high-priority, business-critical services before expanding to the entire ecosystem.
sbb-itb-f9e5962
4. Configuration and IaC-Centric Mapping
Configuration and Infrastructure-as-Code (IaC)-centric mapping creates detailed dependency graphs by analyzing infrastructure code such as Terraform state files, Kubernetes policies, Helm charts, and CI/CD configurations. These graphs capture the intended deployment state of your infrastructure. By integrating with CI/CD pipelines, these maps update automatically whenever new infrastructure changes are pushed, ensuring they stay current. This approach not only identifies direct connections but also uncovers the broader dependency tree, including transitive dependencies like VPCs, DNS configurations, and IAM roles – elements that network traffic analysis often overlooks. This IaC-focused method complements manual, network, and application mapping by grounding dependency graphs in the defined infrastructure state.
Coverage and Freshness
The accuracy of IaC mapping lies in its ability to align the desired state (defined in configuration files) with the actual state observed during runtime. Automated discovery plays a key role here, extracting metadata such as OS versions, IP addresses, ports, and services from cloud, on-premises, and hybrid environments. This eliminates the need for error-prone manual tracking. Additionally, Kubernetes orchestration data enhances the mapping process by providing insights into which services are running on specific nodes.
Operational Complexity
Managing IaC dependencies can be tricky. Tools like Terraform handle implicit dependencies (e.g., referencing module.a.id) effectively, allowing for seamless tracking and planning. However, explicit dependencies (depends_on) often lead to overly cautious resource planning. A common mistake occurs when configurations rely on input arguments (like bucket names) instead of output attributes, which can result in resources being provisioned too early. The challenge becomes even greater when managing dependencies across multiple cloud providers.
Cost Efficiency
IaC mapping isn’t just about clarity – it also saves money. By automating dependency tracking, it eliminates the need for repetitive manual updates, reducing maintenance costs. Since the mapping logic is embedded in the code itself, there’s no need to maintain separate documentation. That said, the initial setup does demand cloud expertise. Drew Firment, VP of Enterprise Strategy at Pluralsight, advises:
Don’t blindly rush into multicloud adoption. The path to realizing its full potential is paved with careful considerations and strategic investments – specifically in cloud training and talent development.
Scalability and Suitability for Multi-Cloud
IaC mapping scales well, especially for multi-cloud environments. By leveraging reusable architecture patterns, this approach handles complexity far better than manual methods. Dependencies are declared once in the code, eliminating the need for repeated documentation. To ensure provisioning happens in the correct sequence, it’s best to rely on implicit dependencies by referencing output attributes rather than known values. Regular audits also help by removing decommissioned resources from the dependency graph. As organizations increasingly adopt multi-cloud strategies, centralizing diverse architectures into a unified IaC framework becomes essential. This is especially true as 71% of business leaders plan to increase their cloud budgets in the coming year.
Pros and Cons
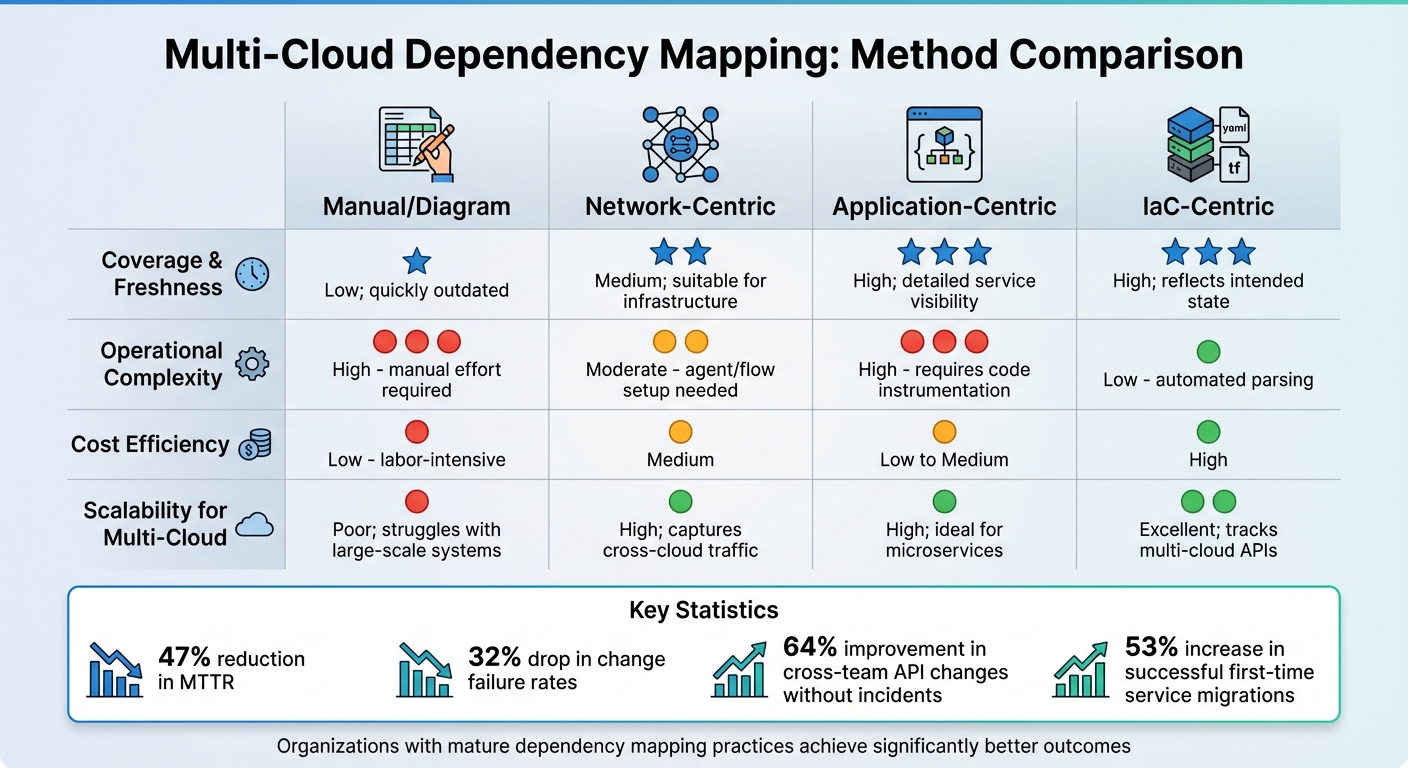
Multi-Cloud Dependency Mapping Methods Comparison: Coverage, Complexity, Cost & Scalability
Each mapping method comes with its own set of strengths and challenges. Manual mapping, for instance, requires significant effort, becomes outdated quickly, and struggles to capture the full complexity of systems. Network-centric discovery strikes a middle ground, offering moderate complexity and reliable coverage of IP-level traffic across cloud environments, making it a solid choice for infrastructure audits. On the other hand, sweep-and-poll methods often miss out on critical real-time insights. Application-centric tracing provides detailed visibility into microservices but demands considerable developer effort for proper instrumentation. Lastly, IaC-centric mapping automates dependency extraction effectively, scaling well with minimal overhead, though it might overlook manually implemented changes.
Organizations that adopt mature dependency mapping practices report impressive outcomes: a 47% reduction in Mean Time to Recovery (MTTR), a 32% drop in change failure rates, and a 64% improvement in cross-team API changes without incidents. Furthermore, teams with high-quality dependency data see a 53% increase in successful first-time service migrations.
| Approach | Coverage & Freshness | Operational Complexity | Cost Efficiency | Scalability for Multi-Cloud |
|---|---|---|---|---|
| Manual/Diagram | Low; quickly outdated | High (manual effort required) | Low (labor-intensive) | Poor; struggles with large-scale systems |
| Network-Centric | Medium; suitable for infrastructure | Moderate (agent/flow setup needed) | Medium | High; captures cross-cloud traffic |
| Application-Centric | High; detailed service visibility | High (requires code instrumentation) | Low to Medium | High; ideal for microservices |
| IaC-Centric | High; reflects intended state | Low (automated parsing) | High | Excellent; tracks multi-cloud APIs |
Conclusion
There’s no one-size-fits-all solution for navigating multi-cloud environments. Manual diagrams quickly become outdated, network-focused tools can miss application logic, tracing often requires significant developer effort, and Infrastructure-as-Code (IaC) mapping might overlook manual adjustments. The reality? A combination of methods is necessary to achieve the level of visibility that growing businesses demand.
A practical strategy involves balancing priorities. The 80/20 approach works well: dedicate 80% of your resources to your primary cloud provider while selectively using others to avoid unnecessary complexity. Start by employing automated tools that capture real-time metadata across your environments – manual tracking just isn’t feasible for modern, dynamic deployments. From there, integrate network flow analysis to monitor critical paths, and use application-level tracing for deeper visibility where it’s most needed. OpenTelemetry can be an excellent choice for instrumentation, helping you avoid vendor lock-in and enabling what AWS refers to as a "two-way door" strategy – letting you switch platforms without rewriting your code.
"If your tooling is dictating your observability strategy, then you need to invert the approach. Tools are meant to enable and empower observability, not to limit your choices." – AWS Observability Best Practices
At TechVZero, managing over 99,000 nodes has taught us that context is more valuable than a single unified dashboard. Tailor your audits by removing unused links, identifying critical failure points, and simplifying overly complex paths. For example, one client saved $333,000 in a single month and stopped a DDoS attack by applying these principles.
To succeed, automate dependency mapping while maintaining context. Embed mapping into your CI/CD pipeline, use Terraform outputs to ensure correct resource ordering, and position telemetry collectors close to workloads to cut down on latency and costs. Most importantly, distinguish between general relationships and critical dependencies to strengthen your system’s most vulnerable areas.
FAQs
What are the advantages of using multiple dependency mapping methods in a multi-cloud environment?
Combining different dependency mapping techniques – like automated configuration mapping, service telemetry, and visual graphing – provides a clear picture of how workloads interact across platforms such as AWS, Azure, GCP, and on-premises systems. By pulling data from tools like network flow analysis and inventory systems, teams can pinpoint hidden vulnerabilities, enhance operational efficiency, and anticipate how problems in one area might ripple across others.
This unified view of dependencies across cloud environments boosts reliability and scalability. It speeds up issue detection, simplifies root-cause analysis, and helps teams make smarter choices about resource allocation and risk management. The outcome? A multi-cloud setup that’s stronger, more efficient, and ready to scale.
How does application-centric mapping enhance reliability and minimize downtime in multi-cloud environments?
Application-centric mapping offers a real-time snapshot of how services, databases, APIs, and infrastructure components work together to support essential business operations. Unlike traditional approaches that focus on hosts or networks, this method zeroes in on application-level relationships. This shift allows teams to trace the entire chain of dependencies and anticipate how failures might ripple through downstream systems. It’s particularly useful in multi-cloud environments where resources are spread across AWS, Azure, GCP, and on-premises setups.
Pairing this mapping with observability tools – like metrics, logs, and traces – gives teams a powerful edge. They can spot issues early, diagnose root causes faster, and minimize downtime. On top of that, it enables proactive planning. Teams can simulate changes or migrations to sidestep unexpected disruptions. This approach helps engineering teams maintain reliable systems without needing deep expertise in infrastructure.
What are the common challenges of using Infrastructure-as-Code (IaC) for dependency mapping in multi-cloud environments?
Using Infrastructure-as-Code (IaC) for dependency mapping in multi-cloud environments comes with its fair share of hurdles. Each cloud provider – whether it’s AWS, Azure, or Google Cloud – uses distinct APIs, naming conventions, and resource management strategies. This lack of standardization makes building a unified inventory tricky without resorting to custom-built solutions. On top of that, tools like Terraform can add layers of complexity. Implicit dependencies don’t always translate seamlessly between providers, while explicit depends_on statements can become fragile as the environment grows in scale. These challenges often lead to configuration drift, where the actual state of the environment no longer matches the IaC definitions, demanding constant monitoring and fixes.
From an operational standpoint, scaling dependency mapping to handle thousands of resources can overwhelm traditional tools. Real-time change detection, while useful, can generate excessive alerts, making it harder to focus on meaningful changes. Visualizing resource relationships across multiple cloud platforms, securely managing secrets, and enforcing consistent policies across providers only add to the complexity. Overcoming these obstacles calls for a disciplined strategy, including well-defined naming conventions, centralized governance, and a robust observability layer to monitor and correlate data across all cloud environments effectively.